
Introduction

Sentiment analysis is the process of determining whether a piece of writing is positive, negative or neutral. It can be used to better understand the users and improve the products. For example, you can understand customer experience towards products on Amazon in their online feedback, or you can identify Twitter’s user sentiment in the tweets they posted.
It’s very easy to use logistic regression to perform sentiment analysis, only 3 steps are needed:
Text data preprocessing
Feature Extraction
Building a logistic regression model
Now, let’s take a look at the details of each step.
Step1: Text Data Preprocessing
There are several steps in text data preprocessing:
Tokenizing the string
It means split the string into individual words without blanks or tabs
Lowercasing
‘HAPPY’, ‘Happy’ -> ‘happy’
Removing stop words and punctuation
Stop words: 'is', 'and', 'a', ‘are’, …
Punctuation: ',', '.', ':', '!', ...
Remove handles and URLs if necessary
@Nickname, Https://...
Stemming
'tuned’', 'tuning', 'tune' -> 'tun'
Step 2: Feature Extraction
The goal is to create a Mx3 feature matrix for all pieces of text data. Each row in the feature matrix represents the feature vector for a writing. M is the number of writing, 3 represents 3 features:
Bias unit. All equal to 1
Sum of positive frequencies for every unique word on writing m
Sum of negative frequencies for every unique word on writing m
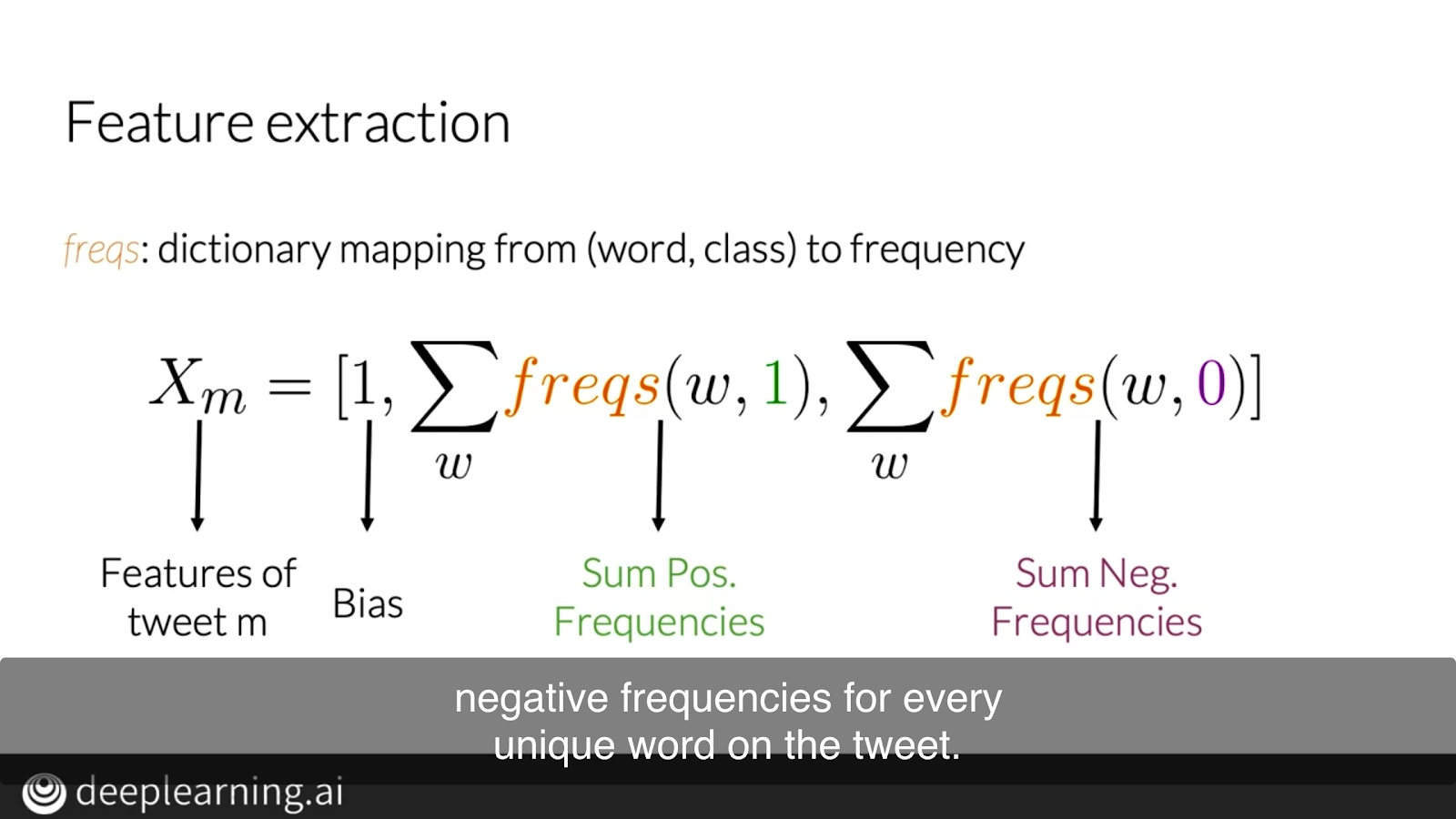
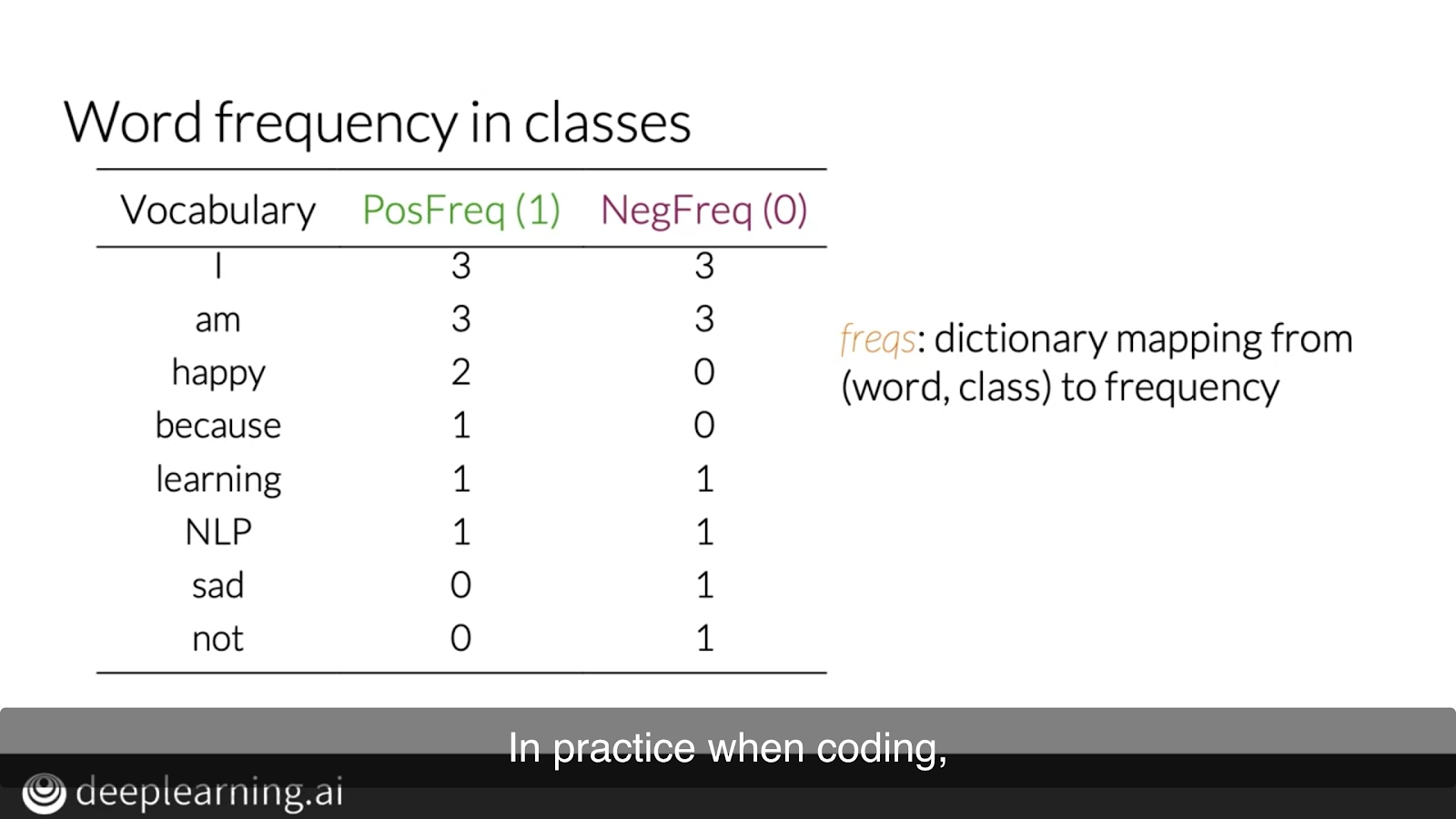
To get this feature matrix, you need to create the frequency dictionary from the processed text data. The keys in this dictionary are pairs of words and sentiment. The values in the dictionary are the frequencies of all the pairs of (word, sentiment).
Take the word ‘cake’ for example, the dictionary will count the frequency of ‘cake’ in positive writings, and the key is (‘cake’, 1), the dictionary will also count the frequency of ‘cake’ in negative writings, and the key is (‘cake’, 0).
As long as you get this frequency dictionary and the processed text data after step 1, you would be able to get a vector representation for each writing using the frequency dictionary mapping. A vector has a bias unit and two additional features that store the sum of the frequencies that every unique word on your processed writings appear in positive writings and the sum of the frequencies they appear in negative ones.
The flow chart below shows the process of step 1 and step 2.
Vocabulary from Raw Data

↓
Frequency of Word in Positive Writings

↓
Frequency of Word in Negative Writings

↓
The Frequency Dictionary that Maps (word, sentiment) to Frequency
↓
Feature Matrix

Step 3: Build a logistic regression model
Use the feature matrix mentioned above as the input matrix
The target variable is binary in this case, telling whether a writing is positive (1) or negative (0)
The logistic regression model aims to learn the best set of estimated parameters for the 3 features which minimize the cost function. During the learning process, the estimated parameters are updated in the direction of gradient of the cost function
This process will repeat again and again until a certain number of iterations and you’ll reach a point (global minimum) near the optimum cost and you will end your training there. This algorithm is also known as gradient descent
After the logistic regression model has been trained, in other words, after you have got the best set of parameters, you can send the product of the estimated parameter and the feature matrix to the sigmoid function to predict your test writings and evaluate the results
Sigmoid function:



Acknowledgements
I learnt all of these from Natural Language Processing with Classification and Vector Spaces several weeks ago, all the pictures in this article are also from this course. I highly recommend Natural Language Processing Specialization on Coursera. This article is a part of my review after this course, I will continue summarizing what I’ve learnt next.
Comments
Post a Comment